.png)
Causal Cooperative Nets: A New Framework for Causal Relationship Discovery
By Jun Ho Park
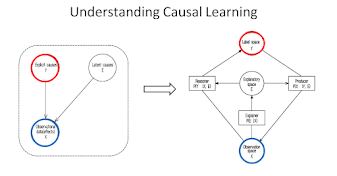
The algorithm has three main components:
- Explainer: The explainer module takes an observation as input and produces a causal explanation of the observation. This explanation can be in the form of a causal graph, a set of causal rules, or any other representation that captures the causal relationships between the variables in the observation.
- Reasoner: The reasoner module takes an observation and a causal explanation as input and produces an inferred label for the observation. This inferred label is based on the causal relationships in the explanation.
- Producer: The producer module takes an inferred label and a causal explanation as input and generates a reconstructed observation. This reconstructed observation is an attempt to recreate the original observation based on the inferred label and the causal relationships in the explanation.
The algorithm is trained to minimize the following losses:
- Inference loss: This loss measures the difference between the reconstructed observation and the original observation.
- Generation loss: This loss measures the difference between the generated observation and the original observation.
- Reconstruction loss: This loss measures the difference between the reconstructed observation and the observation inferred by the reasoner.
The explainer and reasoner modules are trained in a cooperative way. This means that the explainer is trained to produce explanations that are helpful for the reasoner to infer accurate labels. The reasoner is trained to infer labels that are consistent with the causal relationships in the explanations produced by the explainer.
The producer module is trained to generate observations that are consistent with the inferred labels and the causal relationships in the explanations.
The algorithm is trained using the following procedure:
- Forward pass: The explainer produces a causal explanation of the observation. The reasoner then uses the observation and the causal explanation to infer a label for the observation. The producer then uses the inferred label and the causal explanation to generate a reconstructed observation.
- Prediction losses: The inference loss, generation loss, and reconstruction loss are calculated.
- Network errors: The explainer error, reasoner error, and producer error are calculated.
- Backward pass: The gradients of the network errors are calculated and used to update the parameters of the explainer, reasoner, and producer modules.
- Network update: The parameters of the explainer, reasoner, and producer modules are updated.
Once the algorithm is trained, it can be used to infer the causal relationships between the variables in a new observation. To do this, the explainer module is used to produce a causal explanation of the observation. The reasoner module is then used to infer a label for the observation based on the causal explanation.
The causal training algorithm can be used for a variety of tasks, such as:
- Causal discovery: The algorithm can be used to learn the causal relationships between the variables in a dataset.
- Causal inference: The algorithm can be used to
infer the causal effects of interventions on a system. - Causal explanation: The algorithm can be used to explain the predictions of a machine learning model.
.png)
.png)
.png)
Comments
Post a Comment